PRODUCTS WE SUPPORT
 Jira
Jira-
 Jira Service Management
Jira Service Management  Confluence
Confluence Jira Align
Jira Align- ...and more!
TECHNOLOGY INTEGRATIONS
& PARTNERSHIPS
- Atlassian
- AWS
- Appfire
- Tempo
- Carahsoft
- ...and more!


More than ever, organizations are making the cultural and structural changes necessary to embrace DevOps. Fundamentally, DevOps is the concept of tightly integrated collaboration between development and operations teams that relies on an automated toolset. It represents a way of driving increased value to the customer by bringing products to market faster and speeding the rate of releases, all with fewer issues. This transformation, however, is driving increasing demand for IT Service Management (ITSM) support of new products and releases, as well as greater awareness of the role ITSM plays in customer experience, and ultimately, customer satisfaction.
Consequently, as organizations that have embraced DevOps look to the future, their vision is broadening to encompass ITSM as part of this dynamic. There is a growing understanding that development, operations, and service management are an essential, three-legged stool necessary to deliver value to clients. Service management teams are now being recognized for their valuable role in keeping critical business systems, some that drive revenue, up and running. Further, ITSM teams are on the front lines of customer interaction. Often, they are the first to know about issues, and that input is invaluable to DevOps teams, not only to resolving these issues but also to ensuring future releases are more stable and have fewer issues.
While understanding of the value of this three-legged stool—development, operations, and ITSM—is growing, there are some significant barriers to bringing ITSM into the DevOps model. Importantly, ITSM teams are more overburdened than ever, incidents are more complex, harder to identify, and more difficult to resolve. In addition, many organizations are lacking a mechanism for capturing the critical customer insights that ITSM receives and integrating them into the DevOps feedback loop. Solutions do exist, however, and chief among them is replacing the often cobbled-together assortment of both DevOps and ITSM tools with a single, integrated platform that provides better visibility into incidents and issues for not just ITSM teams, but also for development and operations.

We will walk through the increasingly complex environment in which ITSM operates and how it impedes collaboration with development and operations. Then, we will explain how, using a single, shared platform, organizations can overcome the obstacles inherent in this complexity, bridge the gap between DevOps and ITSM, streamline major incident response and problem management, and create a valuable feedback loop between DevOps and ITSM that drives customer value and impacts the bottom line.
In 2011, Marc Andreesen published his groundbreaking essay in the Wall Street Journal, “Why Software is Eating the World.” Nine years later, this observation holds truer today than it did then. We live in an increasingly technology- and software-driven world. As the world at large becomes inextricably software dependent, the world of ITSM has grown increasingly complex. ITSM teams find themselves facing more incidents than ever before, while resolving them is increasingly complex. Key drivers for this complexity include the transition toward more federated application design and the use of microservices; an increased number of mission-critical, SaaS business systems—living both behind and outside the firewall—that need to talk to each other; and a deep understanding of and appreciation for how these business systems drive value—and profits—for organizations.
Organizations today are investing heavily in application design, driven in part by consumer demand for improved performance, functionality, and reliability. Increasingly, organizations are turning away from monolithic applications and embracing a more federated approach to application design using microservice architecture. While microservices bring undeniable benefits—and a big one is that if a microservice goes down, it does not necessarily take down the entire application—they contribute to the complexity and difficulty of diagnosing issues.
ITSM professionals, particularly support engineers with perhaps ten or so years of experience, may recall what it used to be like to get a page that triggered an incident response. While the calls were always likely to cause trepidation, at the time, the response was often scripted. Start with the application itself. Next, move on to the app server, then the physical server. If there were no issues with those layers, then the problem was likely network or database related—both which were likely some other team’s concern. Different teams wholly owned different domains and would handle different types of investigations independently.
That approach has changed significantly as microservices have been introduced. First, multiple teams, in some cases a half-dozen or more, may need to be called in up front just to determine what application is causing a given issue. Further, the issue may not be confined to one microservice. Instead, the issue may be caused by how two or more microservices are talking to each other. So, to diagnose an issue, much less resolve it, may require significant, cross-functional collaboration and communication before teams can drill into and resolve the actual issue.
At the same time, customer expectations are much higher. The kind of outages that were tolerated several years ago when monolithic applications dominated the landscape, are simply too disruptive and too costly now. Taking an entire system down and restarting it is no longer a viable solution—the cost is too great, both in term of customer trust and the bottom line.
 How Organizational Reliance on an Increased Number of Business Systems Drives Complexity
How Organizational Reliance on an Increased Number of Business Systems Drives ComplexityAccording to Okta’s 2020 Business at Work report, respondents to its survey indicate that their organizations use an average of 88 different applications, with 10% of respondents saying their organizations use more than 200. Clearly, organizations today rely on an ever-growing number of applications to power essential parts of their business. It is important to note that among these critical tools are security applications that protect organizations from ransomware, malware, phishing scams, and other IT security threats.
Adding to the complexity of the situation, some are running within the firewall and others outside of it, and many of them need to talk to each other by exchanging information and data. An organization, for example, might have Salesforce hosted externally talking to an ERP hosted on the inside talking to a set of project tools hosted both externally and internally. With these types of complex chains of tools, if an issue occurs, it is not necessarily confined—the effects of that issue ripple downstream.
For the ITSM teams responsible for keeping these tools running and resolving issues, the landscape is infinitely more complex and the stakes are infinitely higher than ever before. Individual ITSM team members would be hard-pressed to be an expert in every domain that they are trying to resolve an issue with, and yet there has never been a greater understanding of the business value of each of these tools.

While DevOps is widely acknowledged as a people-focused cultural shift, it is absolutely one that is enabled by tools that automate processes, and automation is central to its success. From the development perspective, testing, QA, and release processes are all automated, while operations teams automate provisioning of servers, configuring servers, networks and firewalls, and monitoring applications once deployed. Similarly, automation—and the right tools—are essential in managing complexity while bridging the gap between ITSM and DevOps. Simply put, the tools are important.
A single platform that integrates ITSM tools and service desk functionality with DevOps tools offers a number of benefits while also solving a number of problems. We have outlined a few of the most significant challenges and solutions below.
In an effort to streamline issue resolution, many organizations have resorted to cobbling together an assortment of homegrown and commercial applications from a variety of different vendors. While these solutions provide some specific areas of support, building and maintaining integrations between tools can become a significant drain on IT resources. Further, this type of customization can make maintaining and upgrading the tools difficult, resulting in out-of-date functionality and security. Ultimately, this compounds the problem the tools were meant to resolve, and teams find themselves focused on keeping their own systems afloat rather than the high-value tasks they were brought in to perform.
By investing in a single platform, ITSM teams can avoid these “Frankenstein” integrations, since all the tools are either purpose-built to work with each other, or management of the integrations can be outsourced to skilled software vendors with expertise in a given platform. Ultimately, this both reduces the burden of maintaining the tools and shifts the responsibility to external vendors, freeing up valuable ITSM resources—both personnel and hours—to focus on other responsibilities that add greater value to the organization and the bottom line.

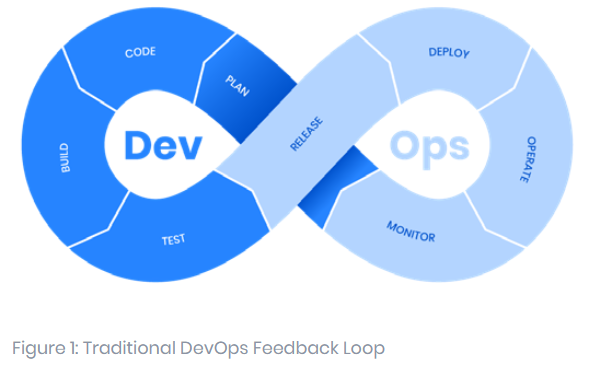
The traditional DevOps infinity loop graphic (Figure 1) shows a continuous process of develop, deploy, and feedback. Indeed, this is a foundational tenet of DevOps principles and central to its success. Still, there is room for improvement. The traditional loop lacks a place for feedback from the very people it is intended to bring value to—the end user. And no one is more connected to the end user than the service desk. DevOps and ITSM teams and importantly, their associated data, are often still highly siloed. When changes are pushed live, and the service desk sees issues occur, there is often no practical way to pull those pieces together for the two teams. In fact, the ITSM team may not even be aware of the changes or recognize patterns as issues develop.
Think about it this way: DevOps is driving more frequent deployments than ever. After those deployments or updates, after incidents, or even after operational changes, service desks are on the front lines in terms of capturing relevant user feedback. However, individual service desk agents may not even be aware of the changes that have been made. Even if they are aware of changes, they may not have the deep familiarity with the software necessary to recognize patterns in incidents or user defects that would contribute to a healthy, continuous DevOps feedback loop. Further, DevOps teams are often totally disconnected from those service desks. Practically speaking, how would that feedback, if indeed the service desk recognized it, make it back to the DevOps teams?
What if ITSM teams could capture that valuable end user feedback in the very same platform where DevOps teams plan and document their processes, thereby alleviating the burden of making disparate systems talk to each other? That is just part of the value of a single platform consisting of underlying tools and powering automated processes that power both DevOps and ITSM. A single platform enables ITSM teams to share information with DevOps teams and allows for them to search for and discover relevant information. This end-to-end visibility brings an inherent layer of knowledge and contextual awareness without teams explicitly having to search for it.
Download Now: How a Single Platform Can Improve DevOps and ITSM Collaboration
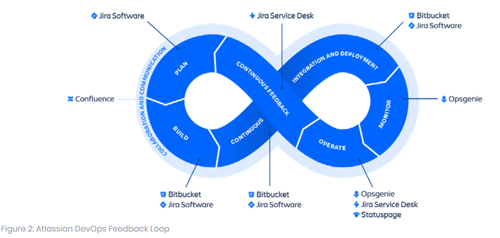
The Atlassian version of the DevOps infinity loop below (Figure 2) shows how, by implementing Jira Service Management (formerly Jira Service Desk), the Atlassian tools already in use daily by development and operations teams across the world can bridge the gap between ITSM and DevOps at the critical feedback stage.
To better understand how the Atlassian platform can streamline the handling of incidents while pushing feedback into the DevOps cycle, we’ll walk through a hypothetical example of an incident and describe how Atlassian tools can be used to streamline management and resolution of the incident while creating visibility into the incident for DevOps teams.
When an incident occurs, information will likely be coming in from a number of sources: users opening tickets, servers throwing errors, applications throwing alerts—even emails coming in. The first step toward resolving these issues is to take in all that noise and make sense of it. That’s where Opsgenie can help. Opsgenie recognizes an incident and gathers all the information, feeding it into a single place, thereby minimizing the noise and enabling the people charged with resolving the incident to focus on the work at hand.
Because Opsgenie is now incorporated into Jira Service Management (JSM), an alert is automatically generated in JSM. Users going to the service desk will see this alert and can click on the notification to learn more.
This takes them to Statuspage where the user community can find more in-depth information about what is happening and follow along from wherever they are, if they choose to do so. Statuspage can even pull in information from relevant third-party applications as necessary. For instance, if Salesforce is experiencing an issue, an organization’s sales team can see that information in Statuspage
.As the incident progresses, Statuspage continuously identifies changes and automatically updates the incident status. This allows internal teams working on the incident to focus on tasks that are critical to resolving it. In addition, end user visibility into the issue results in a better customer experience, one that—despite the incident—engenders confidence in the organization through transparency and responsiveness.
DevOps teams working in the Atlassian platform will likely be using Jira as the command center to orchestrate their work. Since JSM sits on top of Jira, they can be @ mentioned or assigned to the incident so they receive updates. It’s much more straightforward to collaborate on the same platform rather than trying to integrate two platforms or multiple applications and keep them in sync.
Once the incident has been resolved, the status warning goes away. And after that, even the incident postmortem can be done on Confluence. Since everyone is operating on the same platform, the right teams can easily be pulled in, and issues and incidents can be linked so everyone has consistent, complete information to work from.
Ultimately, a single platform with both DevOps and ITSM tools, like those from Atlassian, creates a fully-connected environment that simplifies the complexity ITSM teams face, streamlines incident resolution, and drives end user feedback and insight from the service desk into the DevOps process where those teams can act on it.
One of the most important things smart, fast-moving organizations can do to stay competitive is be much more aware of—and responsive to—customer feedback. Needs are changing more rapidly than ever, so it is critical to hear and respond to feedback just as quickly. Integrating ITSM with DevOps is the key to doing that. But to efficiently plug into the ITSM feedback loop to get closer to customers, understand the impacts of change, and determine where they can make improvements, they must put the appropriate end-to-end platform and processes in place.
The good news is, it’s straightforward to get started. Over the past 10 years or so, as IT teams have adopted first Agile, then DevOps, they have demonstrated the willingness and ability to make significant cultural, structural, and technological changes. More recently, with the COVID-19 pandemic, today’s technology workforces have further demonstrated they are amenable to change, as entirely co-located teams have moved to fully-distributed teams while still delivering good work.
From a technology standpoint, many organizations are already running Jira. From there, Jira Service Management can be up-and-running in minutes with a meaningful deployment in just two to four weeks due to its low-code to no-code nature. By working with an experienced Atlassian partner, the tools can be configured to a given organization’s unique ITSM workflows, while addressing complexity of all types and bridging the gap between ITSM and DevOps.
Ultimately, by embracing what brought them to DevOps and extending that to their approach to IT service management, organizations can incorporate the critical customer feedback into DevOps processes and drive even greater value, further supporting that overarching DevOps principle.